Introduction à DevOps
Introduction
Les applications 12 facteurs
Graphics

Source : https://github.com/kamranahmedse/developer-roadmap

Source : PERIODIC TABLE OF DEVOPS TOOLS (V3)
Méthodes
Agile
Lean
Scrum
DevOps
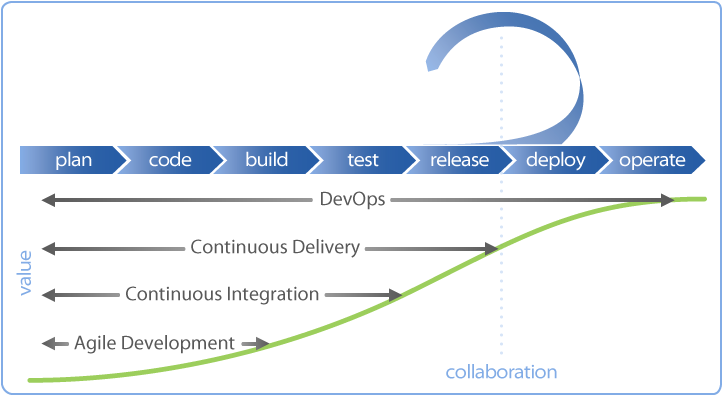
Déploiement continu, livraison continue (CD) et intégration continue (CI) sont un ensemble de pratiques liées à des outils et/ou des services d’usine logicielle et qui relèvent des aspects “agiles” d’un mouvement plus large appelé “Devops”.
Qu’est-ce Devops ?
{==Le mouvement devops est né à la fois de la volonté de globaliser les méthodes agiles à l’ensemble du système d’information et mais aussi de l’application des principes de l’agilité à la production.==}
Il est cependant possible d’être agile dans une équipe uniquement de développement, comme il est possible de mettre en place certains principes devops dans un environnement de développement en cascade. Devops s’appuie sur la méthode Scrum, les principes du Lean Management et met en place les processus ITSM.
!!! info “Définition de Devops”
Devops est la concaténation des trois premières lettres du mot anglais development (développement) et de l’abréviation usuelle ops du mot anglais operations (exploitation), deux fonctions de la gestion des systèmes informatiques qui ont souvent des objectifs contradictoires. Le mot a été inventé par Patrick Debois durant l’organisation des premiers devopsdays à Gand en Belgique, en octobre 2009. Le DevOps est un mouvement visant à l’alignement de l’ensemble des équipes du système d’information sur un objectif commun, à commencer par les équipes de dev ou dev engineers chargés de faire évoluer le système d’information et les ops ou ops engineers responsables des infrastructures (exploitants, administrateurs système, réseau, bases de données,…). Ce qui peut être résumé par “travailler ensemble pour produire de la valeur pour l’entreprise”. 1
CI Intégration continue et CD (déploiement continu et livraison continue)
Qu’est-ce le déploiement continu ?
Le déploiement continu d’une application consiste à le mettre en production dès que tous les tests logiciels ont été réalisés.
!!! info “Définition du déploiement continu” Le déploiement continu peut être considéré comme une extension de l’intégration continue (CI), visant à minimiser délai d’exécution, soit le temps écoulé entre le développement d’une nouvelle ligne de code et l’utilisation de ce nouveau code par les utilisateurs en production. 2
Qu’est-ce la livraison continue (CD) ?
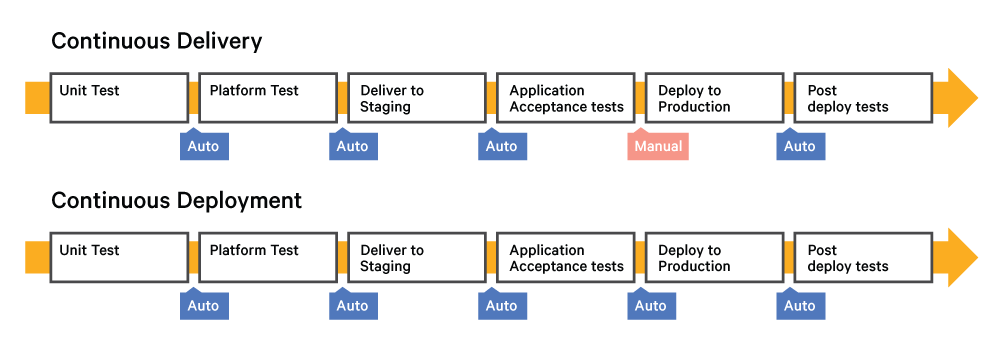
On confond souvent “déploiement continu” (Continuous Deployment) et “livraison continue” (Continuous Delivery).
!!! caution “Livraison continue (Continuous Delivery) versus déploiement continu”
La livraison continue est une suite de pratiques conçues pour garantir que le code peut être déployé rapidement et en toute sécurité vers la production en livrant chaque changement dans un environnement proche de la production et en garantissant que les applications et services métier fonctionnent comme prévu grâce à des tests automatisés rigoureux. Comme chaque modification est fournie à un environnement intermédiaire en utilisant une automatisation complète, vous pouvez avoir l’assurance que l’application peut être déployée en production en appuyant sur un bouton lorsque tout est prêt.
Le déploiement continu est la prochaine étape de la livraison continue : chaque modification qui passe les tests automatisés est automatiquement déployée en production. Le déploiement continu devrait être l’objectif de la plupart des entreprises qui ne sont pas limitées par des exigences réglementaires ou autres. 3
Qu’est-ce que l’intégration continue (CI) ?
Au regard des deux pratiques précédentes, on peut trouver plusieurs définitions de l’intégration continue (CI).
!!! info “Définition de l’intégration continue selon Wikipedia FR”
L’intégration continue repose souvent sur la mise en place d’une brique logicielle permettant l’automatisation de tâches : compilation, tests unitaires et fonctionnels, validation produit, tests de performances… À chaque changement du code, cette brique logicielle va exécuter un ensemble de tâches et produire un ensemble de résultats, que le développeur peut par la suite consulter. Cette intégration permet ainsi de ne pas oublier d’éléments lors de la mise en production et donc ainsi améliorer la qualité du produit. 4
!!! info “Définition de l’intégration continue selon l’Agile Alliance”
Le terme intégration fait référence aux efforts encore nécessaires, après que des programmeurs individuels ou des sous-groupes de programmeurs travaillent sur des composants séparés, pour qu’une équipe de projet fournisse un produit pouvant être livré comme un ensemble fonctionnel. 5
Par exemple, si deux développeurs, travaillant en parallèle, implémentent de nouvelles fonctionnalités sur deux composants A et B, chacun pense à sa satisfaction que le travail est terminé, puis vérifie que les changements à A et B sont cohérents et résout toute incohérence, appartiennent à la catégorie de l’intégration.
Les équipes pratiquant une intégration continue recherchent deux objectifs: d’une part, {==minimiser la durée et l’effort requis par chaque épisode d’intégration==} et, d’autre part, {==être en mesure de livrer une version du produit pouvant être mis à disposition à tout moment==}. En pratique, ce double objectif nécessite une procédure d’intégration reproductible à tout le moins et largement automatisée. Ceci est réalisé grâce à des outils de gestion de version, des politiques et des conventions d’équipe, et des outils spécialement conçus pour aider à réaliser une intégration continue. 6
Serveurs d’intégration continue (CI)
Jenkins, GitLab CI, Buildbot, Drone, Concourse sont des outils CI/CD, 7 mais on en trouvera beaucoup d’autres. 8
La partie CD est à intégrer.
Services CI/CD
- Netlify
- AWS
Principes DevOps
Les trois voies (ou manières) décrivent les valeurs et les philosophies qui encadrent les processus, les procédures, les pratiques de DevOps, ainsi que les étapes normatives.

- Le premier concerne le flux de travail de gauche à droite, du développement aux opérations informatiques.
- Le second concerne le flux constant de retours rapides de droite à gauche à toutes les étapes du flux de valeur.
- La troisième méthode consiste à créer une culture qui favorise deux choses : l’expérimentation continue et la compréhension du fait que la répétition et la pratique sont les conditions préalables à la maîtrise.
1. La Première Voie
La première méthode met l’accent sur le rendement de l’ensemble du système, par opposition au rendement d’un silo de travail ou d’un service particulier - qui peut être aussi important qu’une division (p. ex., Développement ou Opérations de TI) ou aussi petit qu’un contributeur individuel (p. ex., un développeur, un administrateur système).
L’accent est mis sur tous les flux de valeur de l’entreprise qui sont rendus possibles par les IT. En d’autres termes, cela commence lorsque les besoins sont identifiés (par l’entreprise ou le service informatique, par exemple), sont intégrés dans le développement, puis transférés dans les opérations informatiques, où la valeur est ensuite fournie au client sous la forme d’un service.
Les résultats de la mise en pratique de la Première Voie comprennent le fait de ne jamais transmettre un défaut connu aux centres de travail en aval, de ne jamais permettre à l’optimisation locale de créer une dégradation globale, de toujours chercher à augmenter le débit et de toujours chercher à obtenir une compréhension profonde du système (selon Deming).
2. La Seconde Voie
La deuxième méthode consiste à créer des boucles de rétroaction de droite à gauche. L’objectif de presque toutes les initiatives d’amélioration des processus est de raccourcir et d’amplifier les boucles de rétroaction afin que les corrections nécessaires puissent être apportées continuellement.
Les résultats de la deuxième voie comprennent la compréhension et la réponse à tous les clients, internes et externes, la réduction et l’amplification de toutes les boucles de rétroaction et l’intégration des connaissances là où on en a besoin.
3. La Troisième Voie
La troisième voie consiste à créer une culture qui favorise deux choses : l’expérimentation continue, la prise de risques et l’apprentissage de l’échec d’une part, et la compréhension que la répétition et la pratique sont les conditions préalables à la maîtrise d’autre part.
Nous avons besoin de ces deux éléments de la même façon. L’expérimentation et la prise de risques sont les garants de la volonté d’amélioration continue, même si cela signifie aller plus loin dans la zone dangereuse que on ne l’a jamais fait. Et on doit maîtriser les compétences qui peuvent aider à sortir de la zone dangereuse lorsque on est allé trop loin.
Les résultats de la troisième voie comprennent le temps alloué pour l’amélioration du travail quotidien, la création de rituels qui récompensent l’équipe pour avoir pris des risques et l’introduction de failles dans le système pour accroître la résilience.
Source : The Three Ways: The Principles Underpinning DevOps
4. Culture DevOps
- Elements Of The First Way: And The DevOps Implications…
- DevOps Culture (Part 1)
- DevOps Culture (Part 2)
Philosophie et outils DevOps (AWS)

La philosophie culturelle de DevOps
La transition vers le DevOps implique un changement de culture et d’état d’esprit.
Pour simplifier, le DevOps consiste à éliminer les obstacles entre deux équipes traditionnellement isolées l’une de l’autre : l’équipe de développement et l’équipe d’exploitation. Certaines entreprises vont même jusqu’à ne pas avoir d’équipes de développement et d’exploitation séparées, mais des ingénieurs assurant les deux rôles à la fois.
- Avec le DevOps, les deux équipes travaillent en collaboration pour optimiser la productivité des développeurs et la fiabilité des opérations.
- Elles cherchent à communiquer fréquemment, à gagner en efficacité et à améliorer la qualité des services offerts aux clients.
- Elles assument l’entière responsabilité de leurs services, et vont généralement au-delà des rôles ou postes traditionnellement définis en pensant aux besoins de l’utilisateur final et à comment les satisfaire.
- Les équipes d’assurance qualité et de sécurité peuvent également s’intégrer davantage à ces équipes.
Les organisations adoptant un modèle axé sur le DevOps, quelle que soit leur structure organisationnelle, rassemblent des équipes qui considèrent tout le cycle de développement et d’infrastructure comme faisant partie de leurs responsabilités.
Explications à propos des bonnes pratiques concernant DevOps
Il existe quelques pratiques clés pouvant aider les organisations à innover plus rapidement, par le biais de l’automatisation et de la simplification des processus de développement de logiciel et de gestion d’infrastructure. La plupart de ces pratiques sont rendues possibles par l’utilisation des outils appropriés.
Une pratique fondamentale consiste à réaliser des mises à jour très fréquentes, mais de petite taille. Ainsi, les entreprises innovent plus rapidement pour leurs clients. Ces mises à jour sont généralement de nature plus incrémentielle que les mises à jour occasionnelles associées aux pratiques de publication traditionnelles. Le recours à des mises à jour petites, mais fréquentes, limite les risques associés à chaque déploiement. Les équipes ont plus de facilité à détecter les bogues, car il est possible d’identifier le dernier déploiement ayant provoqué l’erreur. Bien que la cadence et la taille des mises à jour soient variables, les entreprises utilisant un modèle de DevOps déploient des mises à jour beaucoup plus fréquemment que les entreprises utilisant des pratiques de développement de logiciel traditionnelles.
Les organisations peuvent également utiliser une architecture de microservices pour rendre leurs applications plus flexibles et favoriser des innovations plus rapides. L’architecture de microservices réduit de grands systèmes complexes pour obtenir des projets simples et indépendants. Les applications sont divisées en plusieurs composants (services) individuels, chaque service étant associé à une mission ou fonction spécifique et exploité indépendamment des autres services et de l’application dans son ensemble. Cette architecture réduit les coûts de coordination liés aux mises à jour d’applications, et quand chaque service est tenu par de petites équipes agiles, les entreprises avancent plus rapidement.
Cependant, l’alliance des microservices et d’une fréquence de publication plus élevée entraîne une augmentation considérable du nombre de déploiements, ce qui peut poser des problèmes opérationnels. Les pratiques de DevOps comme l’intégration continue et la livraison continue résolvent donc ces problèmes et permettent aux entreprises de livrer rapidement de manière fiable et sûre. Les pratiques d’automatisation de l’infrastructure, comme l’infrastructure en tant que code et la gestion de configuration, aident à préserver la souplesse et la réactivité des ressources informatiques face aux modifications fréquentes. En outre, le recours à la supervision et à la journalisation aide les ingénieurs à suivre les performances des applications et de l’infrastructure de manière à réagir rapidement en cas de problème.
Ensemble, ces pratiques aident les entreprises à livrer rapidement des mises à jour plus fiables à leurs clients. Voici une vue d’ensemble des pratiques de DevOps les plus importantes.
Explications à propos de l’intégration continue
L’intégration continue est une méthode de développement de logiciel DevOps avec laquelle les développeurs intègrent régulièrement leurs modifications de code à un référentiel centralisé, suite à quoi des opérations de création et de test sont automatiquement menées. L’intégration continue désigne souvent l’étape de création ou d’intégration du processus de publication de logiciel, et implique un aspect automatisé (un service d’IC ou de création) et un aspect culturel (apprendre à intégrer fréquemment). Les principaux objectifs de l’intégration continue sont de trouver et de corriger plus rapidement les bogues, d’améliorer la qualité des logiciels et de réduire le temps nécessaire pour valider et publier de nouvelles mises à jour de logiciels.
Pourquoi l’intégration continue est-elle nécessaire
Autrefois, les développeurs au sein d’une même équipe avaient tendance à travailler séparément pendant de longues périodes et à n’intégrer leurs modifications au référentiel centralisé qu’après avoir fini de travailler. Cela a rendu la fusion de changement de codes difficile et chronophage, et a également entraîné des bogues pendant une longue période, sans correction. La combinaison de ces différents facteurs empêchait de livrer rapidement des mises à jour aux clients.
Comment fonctionne l’intégration continue
Avec l’intégration continue, les développeurs appliquent régulièrement leurs modifications sur un référentiel partagé, avec un système de contrôle des versions comme Git. Avant d’envoyer leur code, les développeurs peuvent choisir d’exécuter des tests sur des unités locales pour le vérifier davantage avant son l’intégration. Un service d’intégration continue crée et exécute automatiquement des tests unitaires sur les nouveaux changements de codes pour détecter immédiatement n’importe quelle erreur.
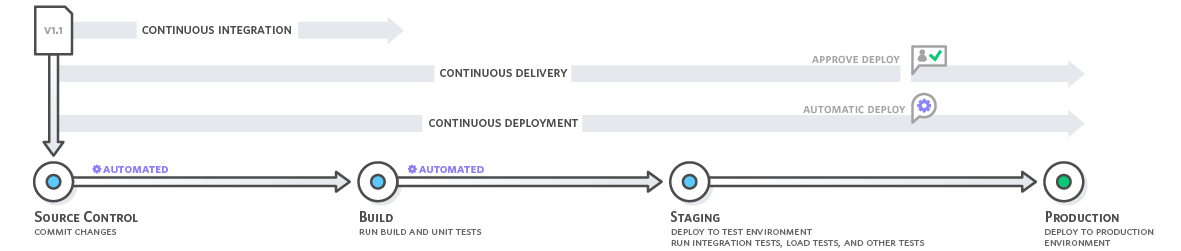
L’intégration continue désigne les étapes de création et de test d’unité du processus de publication de logiciel. Chaque révision appliquée déclenche un processus de création et de test automatisé.
Avec la livraison continue, les modifications de code sont automatiquement appliquées, testées et préparées à la production. La livraison continue étend le principe de l’intégration continue en déployant tous les changements de code dans un environnement de test et/ou un environnement de production après l’étape de création.
Avantages de l’intégration continue
Améliorer la productivité des développeurs

L’intégration continue aide votre équipe à gagner en productivité, en limitant de nombre de tâches manuelles devant être accomplies par les développeurs et en encourageant les comportements qui contribuent à réduire le nombre d’erreurs et de bogues dans les versions publiées auprès des clients.
Trouver et corriger plus rapidement les bogues

Avec des tests plus fréquents, votre équipe peut découvrir et corriger plus rapidement les bogues avant qu’ils ne prennent de l’ampleur.
Livrer plus rapidement des mises à jour

L’intégration continue aide votre équipe à livrer plus rapidement et plus fréquemment des mises à jour après des clients.
Explications à propos de la livraison continue
La livraison continue est une méthode de développement de logiciels DevOps avec laquelle les changements de code sont automatiquement générés, testés et préparés pour une publication dans un environnement de production. Cette pratique étend le principe de l’intégration continue en déployant tous les changements de code dans un environnement de test et/ou un environnement de production après l’étape de création. Une bonne livraison continue permet aux développeurs de toujours disposer d’un artéfact prêt au déploiement après avoir suivi un processus de test normalisé.
La livraison continue permet aux développeurs d’automatiser les tests au-delà des simples tests d’unité, afin de vérifier différents aspects d’une mise à jour d’application avant de la déployer auprès des clients. Il peut s’agir de tests d’interface, de charge, d’intégration, de fiabilité de l’API, etc. De cette manière, les développeurs peuvent vérifier de façon plus complète les mises à jour et détecter les éventuels problèmes à corriger avant le déploiement. Avec le cloud, l’automatisation de la création et de la réplication de plusieurs environnements de test est facile et économique, alors qu’une telle opération serait difficile à mettre en œuvre avec une infrastructure sur site.
Livraison continue vs. déploiement continu
Grâce à la livraison continue, chaque modification de code est appliquée, testée puis envoyée vers un environnement de test ou de préparation hors production. Plusieurs procédures de test peuvent avoir lieu en parallèle avant un déploiement de production. La différence entre la livraison continue et le déploiement continu réside dans la présence d’une approbation manuelle pour mettre à jour et produire. Avec le déploiement continu, la production se fait automatiquement, sans approbation explicite.
Avantages de la livraison continue
En plus des avantages l’intégration continue, la livraison continue a pour avantage :
- Automatiser le processus de publication de logiciel

La livraison continue permet à votre équipe de créer, tester et préparer automatiquement les modifications de code en vue d’une mise en production, afin d’améliorer la rapidité et l’efficacité de vos projets de livraison de logiciel.
Produits AWS CI/CD
Dans une solution Amazon AWS, on configure un flux de travail d’intégration continue avec AWS CodePipeline, qui vous permet de créer un flux de travail qui produit du code dans AWS CodeBuild à chaque fois que vous validez un changement.
1. Microservices
L’architecture de microservices est une approche de conception qui consiste à diviser une application en un ensemble de petits services. Chaque service est exécuté par son propre processus et communique avec les autres services par le biais d’une interface bien définie et à l’aide d’un mécanisme léger, typiquement une interface de programmation d’application (API) HTTP. Les microservices sont conçus autour de capacités métier. Chaque service est dédié à une seule fonction. Vous pouvez utiliser différents frameworks ou langages de programmation pour écrire des microservices et les déployer indépendamment, en tant que service unique ou en tant que groupe de services.
Produits AWS microservices
- Amazon Container Service (ECS) : Service de conteneurs logiciels.
- AWS Lambda : exécution de code à la demande.
2. Infrastructure en tant que code
L’infrastructure en tant que code est une pratique qui implique la mise en service et la gestion de l’infrastructure à l’aide de code et de techniques de développement de logiciel, notamment le contrôle des versions et l’intégration continue. Le modèle axé sur les API du cloud permet aux développeurs et aux administrateurs système d’interagir avec l’infrastructure de manière programmatique et à n’importe quelle échelle, au lieu de devoir installer et configurer manuellement chaque ressource. Ainsi, les ingénieurs peuvent créer une interface avec l’infrastructure à l’aide d’outils de code et traiter l’infrastructure de la même manière qu’un code d’application. Puisqu’ils sont définis par du code, l’infrastructure et les serveurs peuvent être rapidement déployés à l’aide de modèles standardisés, mis à jour avec les derniers patchs et les dernières versions, ou dupliqués de manière répétable.
Le produit AWS CloudFormation est un outil qui permet de gérer une infrastructure en tant que code.
Gestion de configuration
Les développeurs et les administrateurs système utilisent du code pour automatiser la configuration du système d’exploitation et de l’hôte, les tâches opérationnelles et bien plus encore. Le recours au code permet de rendre les changements de configuration répétables et standardisés. Les développeurs et les administrateurs système ne sont plus tenus de configurer manuellement les systèmes d’exploitation, les applications système ou les logiciels de serveur.
Le produit Amazon EC2 Systems Manager permet de configurer et de gérer des systèmes Amazon EC2.
Le produit AWS OpsWorks offre des fonctions de gestion des configuration.
3. Consignation et supervision
Les entreprises suivent les métriques et les journaux pour découvrir l’impact des performances de l’application et de l’infrastructure sur l’expérience de l’utilisateur final du produit.
En capturant, catégorisant et analysant les données et les journaux générés par les applications et l’infrastructure, les organisations comprennent l’effet des modifications ou des mises à jour sur les utilisateurs, afin d’identifier les véritables causes de problèmes ou de changements imprévus.
La supervision active est de plus en plus importante, car les services doivent aujourd’hui être disponibles 24 heures sur 24 et la fréquence des mises à jour d’infrastructure augmente sans cesse. La création d’alerte et l’analyse en temps réel de ces données aident également les entreprises à suivre leurs services de manière plus proactive.
Le produit Amazon CloudWatch permet de surveiller les métriques et journaux d’une infrastructure.
Le produit AWS CloudTrail permet d’enregistrer et de journaliser les appels d’API AWS.
4. Communication et collaboration
L’instauration d’une meilleure collaboration et communication au sein de l’entreprise est un des principaux aspects culturels du DevOps. Le recours aux outils de DevOps et l’automatisation du processus de livraison de logiciel établit la collaboration en rapprochant physiquement les workflows et les responsabilités des équipes de développement et d’exploitation.
Partant de cela, ces équipes instaurent des normes culturelles importantes autour du partager des informations et de la facilitation des communications par le biais d’applications de messagerie, de systèmes de suivi des problèmes ou des projets et de wikis. Cela permet d’accélérer les communications entre les équipes de développement et d’exploitation et même d’autres services comme le marketing et les ventes, afin d’aligner chaque composant de l’entreprise sur des objectifs et des projets communs.
Exemple de configuration d’un pipeline de CI/CD sur AWS
https://aws.amazon.com/fr/getting-started/projects/set-up-ci-cd-pipeline/
Dans ce projet, on découvre comment configurer un pipeline d’intégration et de livraison continues (CI/CD) sur AWS. Un pipeline aide à automatiser les étapes du processus de publication de logiciel, comme lancer les versions automatiques et les déployer ensuite sur les instances Amazon EC2.
On utilisera AWS CodePipeline pour créer, tester et déployer le code chaque fois que celui-ci est modifié, en fonction des modèles de processus de publication que l’on a définis.

Architecture Microservices
Les microservices sont un type d’architecture logicielle SOA “à partir duquel un ensemble complexe d’applications est décomposé en plusieurs processus indépendants et faiblement couplés, souvent spécialisés dans une seule tâche. Les processus indépendants communiquent les uns avec les autres en utilisant des API langage-agnostiques.”
Le sujet est réellement évoqué à partir de 2014 selon Google Trends.
Quelle est la différence entre des microservices et des Web services ? Alors Web services fournissent toujours des services via HTTP à travers le World Wide Web, les microservices peuvent fonctionner sur des réseaux non HTTP, communiquer via des API, être servis via des descripteurs de fichiers, ou être développés sur des messages ou des e-mails.
Les applications à architecture monolithique
L’application est construite comme une unité complète où les fonctions et les services sont étroitement liés. Lorsqu’une erreur est générée et n’est pas traitée correctement, l’unité entière, y compris les services qui ne sont pas liés à l’erreur, sera désactivée. De plus, pour que tout changement de code ou mise à jour de version sur un seul service prenne effet, un redémarrage de l’ensemble du monolithe (y compris tous les autres services !) sera nécessaire.
Les applications à architecture en microservices
Le problème de “scalability” (évolutivité), de mise à l’échelle, des architectures monolithiques ne se rencontre pas dans les architectures en microservices. En effet, chaque service étant un composant découplé et auto-contenu, la génération d’une erreur dans un service seront traitées immédiatement. De manière semblable, la mise à jour du code d’un service ne nécessitera que le redémarrage du service concerné.
Différents stacks de développement peuvent être utilisés pour construire ces services en tant qu’entités autonomes à condition que ceux-ci puissent communiquer entre eux via des APIs bien définie et disponibles. Un service programmé en Go, un autre en JavaScript et encore un autre en PHP.
La mise à l’échelle d’une application sera également améliorée, chaque service pouvant être mise à l’échelle indépendamment. Supposons que le trafic sur le service A ait considérablement augmenté au cours des 5 dernières minutes et qu’il a maintenant du mal à faire face à l’augmentation du nombre de demandes en raison d’un manque de CPU. Ce problème peut être immédiatement corrigé en augmentant les ressources du service A. Une fois de plus, les autres services ne seront pas touchés.
Avantages
- Les services individuels sont simples à remplacer
- Le niveau de service est indépendant des cycles de développement
- Les services sont conçus pour leur utilité spécifique (par exemple la facturation, la chaîne logistique, l’interface…)
- L’architecture est plus symétrique que hiérarchique (passage d’une architecture client-serveur à une architecture de plusieurs entités communicantes)
- L’architecture facilite le déploiement continu du code
- Délai de déploiement réduit
- Différents stack de programmation peuvent être utilisé
- Isolation des erreurs
- Mise à l’échelle améliorée
Serverless Cloud Computing
Serverless computing est une méthode pour fournir des services d’application de backend sur base de l’usage et à la demande. Un fournisseur Serverless permet aux utilisateurs d’écrire et de déployer du code sans se soucier de l’infrastructure sous-jacente à son exécution. Le client est facturé en fonction de l’usage uniquement sans avoir à réserver des ressources à coûts fixes. Bien que le terme suggère l’absence de serveurs physiques ceux-ci sont bien présents mais entièrement pris en charge par le fournisseur et ne font plus partie des soucis des développeurs.
Dans les premiers d’Internet, tout qui voulait héberger un service Web devait posséder son propre serveur physique. (…)
Exemple de Serverless Computing
- DaaS
- SaaS
- FaaS
Avantages du Serverless Computing
- Coûts réduits - paiement uniquement à l’usage
- Mise à l’échelle simplifiée - Les développeurs utilisant une architecture Serverless n’ont pas à se soucier de la mise à niveau leur code. Le fournisseur de services sans serveur prend en charge l’ensemble de la mise à l’échelle à la demande.
- Code back-end simplifié - Avec FaaS, les développeurs peuvent créer des fonctions simples qui exécutent indépendamment un seul but, comme faire un appel API.
- Délais d’exécution plus rapides - L’architecture sans serveur permet de réduire considérablement les délais time to market. Au lieu d’avoir besoin d’un processus de déploiement compliqué pour déployer des corrections de bogues et de nouvelles fonctionnalités, les développeurs peuvent ajouter et modifier du code sur une base fragmentaire.
Exemples FaaS
- AWS Lambda
- IBM Cloud Functions
- Microsoft Azure Functions
Technologies de conteneurs
- Container Engine
- Container Orchestration
Docker
Kubernetes
PaaS
FaaS
Illustration de la fonction Lambda sur Neltify :
Create your own URL shortener with Netlify’s Forms and Functions : https://linkylinky.netlify.com/ dont l’application : https://shortener.eu/.
- Définition Devops de Wikipedia FR [return]
- Défintion de la notion de déploiement continu par l’Agile Alliance [return]
- Puppet blog Continuous Delivery Vs. Continuous Deployment: What’s the Diff?. [return]
- Définition de l’intégration continue selon selon Wikipedia FR : https://fr.wikipedia.org/wiki/Int%C3%A9gration_continue. [return]
- Définition de l’intégration selon l’Agile Alliance [return]
- Définition de l’intégration continue selon l’Agile Alliance. [return]
- Comparatif des outils CI/CD Digital Ocean. [return]
- Référence manquante. [return]